ClickHouse 在商业中台的实践和应用
1.背景
在订单中台干了两年之后由于工作关系的变动我入职了一家以广告为核心业务的公司,所在部门属于商业中台,但是由于业务架构的调整,原先大数据部门面临重组,我们急需满足商业业务相关的数据需求。但是由于原有架构为传统CDH集群且机器管理混乱,很多配置和脚本并不是一个工程化的方案,同样的我们亟待重构和适应当前业务体系。在探寻当前热门OLAP解决方案时,ClickHouse出现在了我们的视野。
同样出现在我们面前的选择还有阿里云主推的ADB,以及以查询高效的Druid。但最终我们依旧选择ClickHouse作为我们实时数仓的解决方案。主要选择的原因集中在以下几点:
1.轻量级、高可用
2.查询性能高,支持实时分析
3.查询语法贴近MySQL,对Mysql交互有一定支持
出现以上选择的考量一方面是团队对大数据处理没有丰富的经验(我就是第一次),另一方面考虑到运维成本,最终在经过数周的检验之后我们建立我们的第一个ClickHouse集群。
2.最佳实践
由于一些历史原因,我们使用的版本是:20.9.2.20 所以以下内容的实践,均基于此版本。
2.1 数据写入
我们为了降低复杂度尽可能的缩短数据链路,所以我们采取了以下的方式写入:
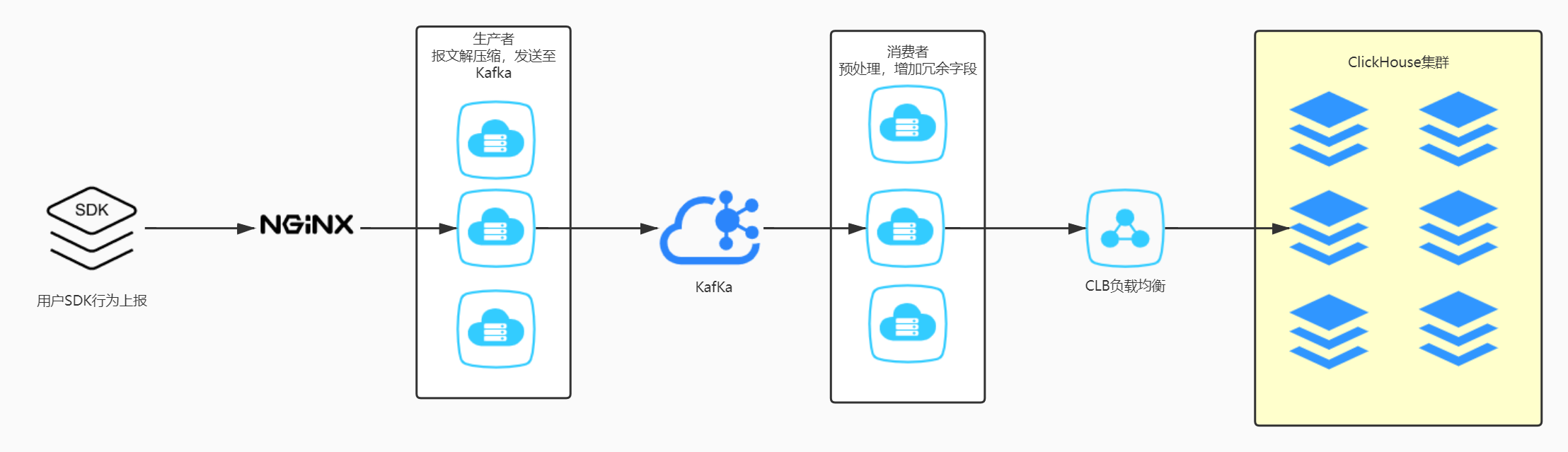
这里ODS层我们采取6分片各自2台、使用副本机制的高可用版本,底层表通过CLB做负载均衡分别写入到本地表。底层行为日志由于是时间维度,采用时间+应用的方式来分区。查询的时候使用其分布式表来做。
写入的瓶颈在于如何减少ClickHouse的异步merge(低量高频的写入可能会引发Too many part merge此类错误),需要选择合适的INSERT BATCH,尽量在程序就完成Merge操作,批量写入(5000-20000 条)。
以上链路每天处理数据平均在120亿上下,半年内稳定运行。
2.2 数据清洗、更新
由于ClickHouse 没有OVERWRITE这样的覆写方式,所以我们采用分区操作来完成数据的覆盖更新:
1. ALTER TABLE dwd.target_table_temp DROP PARTITION '$PART'
2. INSERT INTO dwd.target_table_temp;
3. ALTER TABLE dwd.target_table REPLACE PARTITION '$PART' FROM dwd.target_table_temp;
这样的更新方式虽然比较占用空间,但是对于有些底层的清洗表而言需要这样的更新,有人问为什么不使用去重引擎去做同样的事情呢?去重引擎固然简单,但是有个很大的缺陷:去重引擎是单分片的操作,对于分布式多分片的表而言是无效的,且去重的过程是异步的,很难确定去重需要多久能够完成,往往需要去查看system.process 来确认执行情况。
我们在业务量级每日100w+的业务订单中使用了去重引擎,原因有以下:
1. 订单的去重主键更加简单,不同于业务上对于用户去重主键的认定。、
2. 数据量级小,无需使用多分片多台来提升写入性能
3. 业务订单由于产品矩阵巨大,很难使用导入Mysql的方式来完成数据实时导入
使用方式如下:
创建本地表:
create table dwd.withdraw_s1_local
(
logday Date,
product String,
product_name String,
product_group String,
order_no String,
user_id Int64,
.....
)
engine = ReplacingMergeTree()
PARTITION BY logday
ORDER BY order_no
SETTINGS index_granularity = 8192;
程序批量写入,然后任务确认合并状况:
flag = True
start = int(time.time() * 1000)
while flag:
sql_check=r"select if(count(1)>0,1,0) from (select order_no,count(1) as c from dwd.withdraw_s1_local group by order_no having c > 1) group by 1;"
res = client.execute(sql_check)
if res[0][0] == 1:
sql_deduplicate=r"optimize table dwd.withdraw_s1_local deduplicate;"
client.execute(sql_deduplicate)
print("已提交表重复项合并... 请等待30s")
time.sleep(30)
print("开始重新查询重复项....")
else:
flag = False
print(">>>> 表已合并完成...本次耗时 {}ms".format( int(time.time() * 1000) - start))
然后将本地表中的数据写入新的分布式表,后续的查询都使用分布式表。
数据实时更新的问题依靠以上的方式基本上都解决了。
2.3 计算留存
留存计算可以说是每家用户行为分析都会遇到的一个问题,但其在CK的解决方式存在多个思路,因地制宜。
业务初期对ClickHouse了解并不深入,使用LEFT JOIN的方案来实现了留存的查询,但是对于ClickHouse而言JOIN并不是很优雅,并无法发挥其查询的优势,所以在此基础了,对留存的方案进行了改进:
select sum(r[1]) as t1,
sum(r[2]) as t2,
sum(r[3]) as t3
from (
select retention(
logday = toDate('__logday__') - 2,
logday = toDate('__logday__') - 1,
logday = toDate('__logday__')) r
from dwd.device_active
where product = '{}'
and os = '{}'
and logday = toDate('__logday__')
group by device_id);
上述SQL利用了ClickHouse的高阶函数 retention :
retention(cond1, cond2, ..., cond32);
The conditions, except the first, apply in pairs: the result of the second will be true if the first and second are true, of the third if the first and third are true, etc.
正如文档所说,retention 可以使后面的条件在满足的同时且满足cond1时 返回1,所以通过此函数一举可以求出用户的留存。
但是由于业务发展和需要,数据需要计算用户的90日留存,上述方案的执行效率不再能够被接受,所以在这里参考了之前腾讯的解决方案:ClickHouse留存分析工具十亿数据秒级查询方案
针对腾讯的思路在我们得出以下流程:我们将留存查询的维度建聚合表:
-- 新增设备
create table dwd.aggregation_device
(
logday Date,
product String,
os String,
device_bit AggregateFunction(groupBitmap, UInt32)
)
engine = AggregatingMergeTree()
PARTITION BY logday
ORDER BY (product, os)
SETTINGS index_granularity = 8192;
写入:
insert into dwd.aggregation_device
select logday, product, os, groupBitmapState(xxHash32(device_id))
from dwd.device_full_dist
where logday = '$day'
group by logday, product, os;
活跃设备:
create table dwd.aggregation_device_au
(
logday Date,
product String,
os String,
device_bit AggregateFunction(groupBitmap, UInt32)
)
engine = AggregatingMergeTree()
PARTITION BY logday
ORDER BY (product, os)
SETTINGS index_granularity = 8192;
insert into dwd.aggregation_device_au
select logday, product, os, groupBitmapState(xxHash32(device_id))
from dwd.au_device_full_dist
where logday = '$day'
group by logday, product, os;
查询新增设备query_day留存:
select bitmapCardinality((select device_bit from dwd.aggregation_device
where logday = 'query_day' and product = 'product' and os = 'android'
)) as r0,
bitmapAndCardinality(
(select device_bit
from dwd.aggregation_device
where logday = '2query_day' and product = 'product' and os = 'android'),
(select device_bit
from dwd.aggregation_device_au
where logday = yesterday() and product = 'product' and os = 'android')
) as r1,
r1 / r0;
此方案突显出一个查询速度快,借用维度强悍的性能,压缩以后的设备存储空间也非常小(三个月活跃设备8亿数据最终占用空间1.8G),查询耗时基本在20ms左右(90日留存使用原方式Join表数据就得半小时上下。)
2.4 计算日龄
用户日龄在业务上定义为新增用户日龄和活跃用户日龄。即用户从注册到今日相隔日期以及活跃的天数是哪些天。计算这个指标对我们完成LTV、用户ARPU等指标的计算有很大的帮助,如果依旧使用Join的思路依旧处理十分低效,这里依旧使用Aggregate Functions来帮助我们完成日龄计算。
基于设备建表:
create table dwd.aggregation_device_age
(
product String,
os String,
device_id String,
age AggregateFunction(uniqExact, Date),
dayGroup AggregateFunction(groupUniqArray, Date),
lastDay AggregateFunction(max, Date)
)
engine = AggregatingMergeTree()
PARTITION BY product
ORDER BY (product, os, device_id)
SETTINGS index_granularity = 8192;
写入:
insert into dwd.aggregation_device_age
select product,
os,
device_id,
uniqExactState(logday) as age,
groupUniqArrayState(logday) as dayGroup,
maxState(logday) as lastDay
from dwd.au_device_dist
where logday = '{}'
group by product, os, device_id
查询时计算天数即可:
select product,
device_id,
os,
groupUniqArrayMerge(dayGroup) as dayArray,
arrayFirst(x-> isNotNull(x), arraySort(dayArray)) as firstDay,
arrayFirst(x-> isNotNull(x), arrayReverseSort(dayArray)) as lastDay,
lastDay - firstDay + 1 as dayBetween
from dwd.aggregation_device_age
group by product, device_id, os
这样避免了JOIN表,可以说是留存的不同维度的变式。
2.5 Mysql交互
在这里只简单对Mysql表引擎和Mysql库引擎做一下使用的介绍,今年初ClickHouse推出了更强劲的实验库引擎:MaterializeMySQL 由于没有上手体验,这里挂个官网地址方便大家了解:MaterializeMySQL.
Mysql表引擎方便了我们从Mysql获取最新的数据,但是由于不和Mysql保持同步,所以说数据内容即拉取那一刻得到的数据,在ClickHouse的修改并不会影响到Mysql中内容,而库引擎则会同步这个库所有的表,他会与Msyql保持实时连接,但是无法执行RENAME CREATE ALTER 这些操作,但是支持INSERT ,所以这里可以利用这个特性来发起ClickHouse到Mysql的数据导出。
剩余的业务问题不太适合出现在Ck的篇幅当中,我们再看看运维相关的.
3.集群运维
ClickHouse 在市面上开源的运维平台并不多,Ckman是其中比较优秀的一款,但是由于还在高速迭代的过程当中,所以对于老集群的管理、集群配置修改、用户交互等方面可能还是不太完善,所以这里主要挑一个比较重要的指标,来让我们观测集群整体的状态,来判断Clickhouse是否能够正常处理的我们的业务。
4.1 集群监控
ClickHouse我们所关注的无非三大块:
1.CPU
2.内存
3.I/O
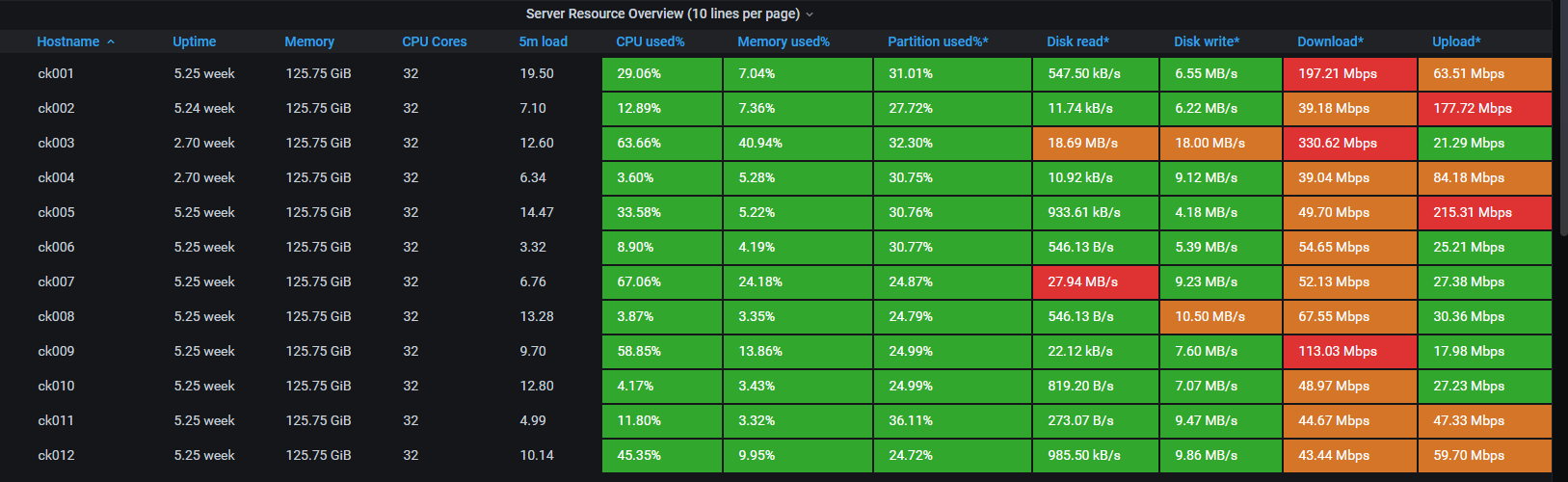
查询是否迅速、写入是否异常往往大都与这三个方面相关,这里我们借助Prometheus来做相关的监控。可以在ClickHouse的机器安装node_exporter,这个的安装和配置我就不赘述了,然后从Grafana官网扒一个监控模板,就能轻易看到以下指标:
1.CPU、内存、存储
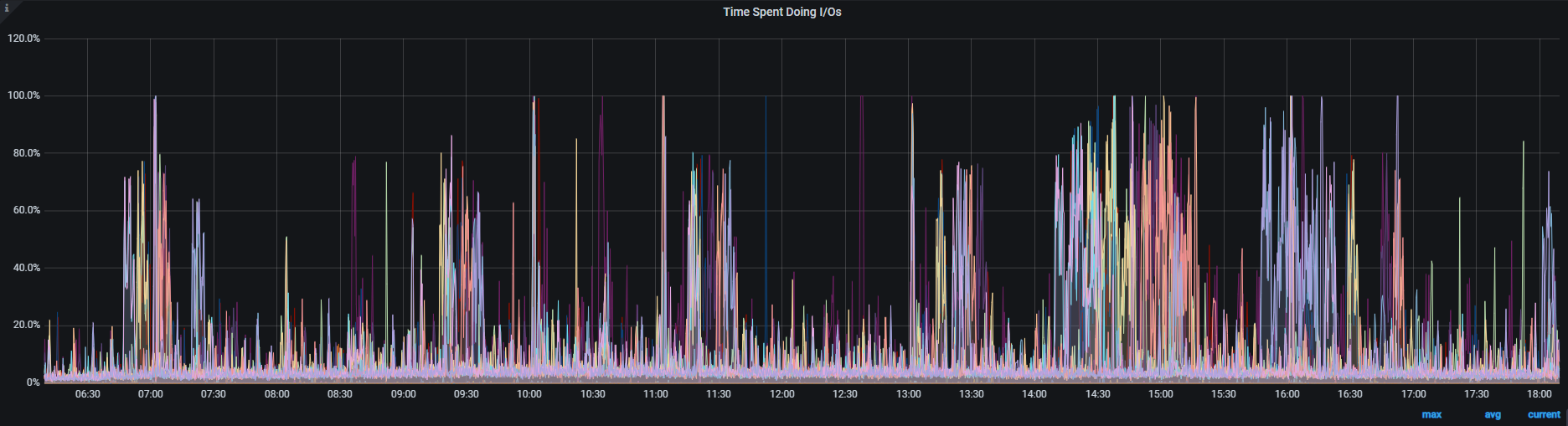
2.I/O状态
3.ERROR LOG(取自system.query_log)
4.表状态(取自system.parts)
5.当前会话进程(取自system.process)
4.2 Zookeeper 相关监控
为什么要监控ZK呢?由于ClickHouse的Metadata和分片的高可用以及分布式命令的执行都依赖ZooKeeper的稳定性,所以监控Zookeeper对于维护Clickhouse的稳定性十分重要。

这里同样的监控通用的指标,但是除此之外需要看下Zookeeper的Jvm相关状态。
4.3 扩容和配置变更
ClickHouse的扩容是非常人性化的,无需重启就可以完成扩容加分片、部分配置修改:
1.分片配置修改
<!-- metrika.xml -->
<yandex>
<clickhouse_remote_servers>
<cluster-1>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ck001</host>
<port>9000</port>
<user>**</user>
<password>**</password>
</replica>
<replica>
<host>ck002</host>
<port>9000</port>
<user>**</user>
<password>**</password>
</replica>
</shard>
<!-- 其余SHARD -->
</cluster-1>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>ck-zk1</host>
<port>2181</port>
</node>
<node index="2">
...
</node>
</zookeeper-servers>
<macros>
<cluster>cluster-x</cluster>
<replica>s2r1</replica>
<shard>s2</shard>
</macros>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
2.配置等修改(日志、会话过期、监控等方面):config.xml
这方面,官网专业,所以基本上看官网就好...
4.4 常见异常和处理方式
- 删除表 ZK replicas未同步:
> DB::Exception: Replica /clickhouse/tables/s1/dwd/xxxx/replicas/s1r1 already exists..
> A: 连上ZK deleteAll 直接OK - 无法执行DDL(alter)
> Cannot execute replicated DDL query on leader;
> 这里原因比较多,后面有详细的报文,按照提示来,如果是表太大,先按照分区DROP一部分再DROP TABLE,如果是其他的,具体问题具体对待 - 删除分区/INSERT过快导致节点关闭(分布式DDL卡死):
> Cannot execute replicated DDL query, maximum retires exceede Watching task /clickhouse/task_queue/ddl/query-0000000609 is executing longer than distributed_ddl_task_timeout (=180) seconds
> CK的config.xml有自动清除task_queue的配置,但是默认是不生效的,建议自己加上。如果已经满了,可以查看system.zookeeper看下,执行不了就老办法,上ZKClient,deleteall,然后重启clickhosue - ZK过载/连接丢失导致的分布式表只读、会话失效:
> DB::Exception: Table is in readonly mode.
> 表只读了,建议先停止写入,然后看后台日志,Merge结束了再打开。
> ZooKeeper session has been expired.
> ZK会话过期,频繁出现看看你的SQL DDL是不是太迅捷了。正常请况下是不会有的
> Cannot allocate block number in ZooKeeper: Coordination::Exception: Connection loss
> Zk麻了,建议升级Zookeeper配置,能力上去了就不会 create node失败了。
4.总结
写到最后不得感叹下,ClickHouse帮助我这个从来没有接触过如此量级数据的Java程序员较好的完成相关的业务任务,其本身的素质是十分过硬的,但是由于最近两年才在国内兴起,相关的中文资料不是很完善,对比同档次的其他OLAP这方面可能略微差一点,但是其开源氛围是相当不错(英文的文档也还挺敬业),曾经发生的数次异常都在Github Issue得到了及时的解答和帮助。ClickHouse也在支持越来越多的功能(比如今年在新版本开放的窗口函数),也逐渐在往好的方向走去。上面写的一些方案可能不是最优解(非专业数据参考得来的方案),大家也可以指出~我及时修改。
联系邮箱 work@kelovp.tech
可以求一下监控的dashboard编号吗?
@bjddd192 https://grafana.com/grafana/dashboards/8919
这个
啥也不说了,希望疫情早点结束吧!