大面积服务雪崩,复盘后发现原因竟是它
今天是2019-11-26 我重新开始修改以前写过的Blog,或许,这一年我的收获和成长就从这里开始。回首观望,一年里我都在为自己心中所谓的操守执行履约,孰对孰错,事已至此,抛开不谈。再看过往,的确是自己发生了变化。博客虽然是写给自己看的[笑],但是也总是在内心希望,有人能看到我的故事,我的2019,我这失败而又充满无奈的一年[无奈]。当然我心里也明白,之前写的这篇也是在甩锅,慢SQL是存在的,但绝对不是文中的这条,我们只需要一个能解决的理由和正常运行的程序(这是我非常不赞成态度,但是鉴于至今仍然没看到那句来自运维MYSQLDB的慢SQL日志,所以文中的SQL只是背锅侠 [其本身也复杂,适合背锅] ,更多的还是当瓜吃吧,这事过去快一年了,所以才会发出来 [我才不会说我写了十几篇文章全是这种,见光或许会死的...玩笑话,当饭后甜点恰就行昂] )
前言
作为APP的后端,一些固定的数据页面往往内容复杂,而究其作用,往往是信息传递,讲通俗点就是高频次查询,低频更新。而往往为了高效和合理,这部分的数据后端通常使用缓存,这里的缓存不论是APP的文件缓存,还是后端接口的服务器内存缓存,还是Redis这样高效的内存数据库缓存,甚至MYSQLDB的缓存,都是在为重复的操作提供高效的返回。而在构建这样的缓存系统时,经常有几个非常刺眼的问题,而不注意这些细节的人,几乎都会翻车:机器是诚实的,代码错误他就会返回错误的结果,哪怕是概率性的问题,他也会在对应的概率范围内准时出现。不巧的是,我在1月20日正好遇到的这样的灾难。
1.变故
我和往常一样,在十点钟对着昨天晚上的邮件发呆,哪怕是快到春节封版,PM也不放过这短短的几天时光,想在这局促的几天里上线一版自己的业绩版本,希望自己能过个好年。当我正在一行一行扫描需求文档的时候突然一条消息弹窗出现在眼前
“我们的APP是出什么问题了吗?打开后都是白屏”
我看了一眼问题反馈群当中的截图和录屏,loading图标和1.4MB的下载计速格格不入。的确,我们的系统像是出问题了。
于是只能打开日志,想看看首页的接口出了什么问题。
不巧的是,当我使用tail -f 想浏览日志文件的时候更严重的问题出现了:日志定格在了五分钟之前,最新的一条还是DB链接获取失败的错误堆栈。我有点慌神的打开了其他的服务的日志:糟了!只有个别服务还在正常运行,大部分服务都已经宕了!
这个时候运维显然已经发现了问题,他紧皱着眉头说了一句话:我们的主库宕了....大家都倒吸口凉气,我们毕竟小公司,以前并没有互联网常用的分库分表、读写分离(业务量决定单库也能玩转),而对应的监控体系也很弱鸡(弱鸡是夸赞,因为事实是根本没有,所以我们发现的才如此之慢)。而主库宕机的原因,初步推测是慢SQL,而在宕机时刻开始执行的SQL有几百条,过滤掉一部分之后还需要点时间来甄别到底是哪条,而线上的服务处于不可用状态。而解决线上问题的基本原则之一就是:保证用户的可用状态!
2.排查
显然最快的方式就是重启!运维和几个开发迅速开始了服务重启,包括DB和对应的Java应用。而在重启之后不到三分钟,连接数又达到了MaxSIze!服务又重新处于了不可用状态。而此刻我们显然有点着急了,因为首先没有找到问题的根源,也没有找到慢sql的具体条目,没有发现祸根重启之后还是依旧会引发病态。
运维只能逐个排查,而在排查过程中我们也只能通过集成了阿里云日志的系统来分析分析,到底是多么优雅的一条SQL,威力如此强劲。而来来去去日志最终定格在了一条更新缓存的定时任务身上:每个小时的开章它都在勤勤恳恳的调用内部系统接口,来更新业务的系统的展示性质数据,而到了早晨的九点钟,他却迟迟没有行动,再到后来,它干脆消失在了日志当中。而它在临终前留下了一条信息:一个调用内部系统查询的接口。
看到这个接口之后(它来了 它来了,背锅SQL要来了)我眉头一皱:一个大约五十行的sql,里面的 关键字包含了join/left/datadiff/formate等等,关键不是在关键字,而是其连表的个数超乎我的想象,大约八九张花花绿绿的表连在一起,而查询条件里又是一些意义不明的数字。而这个sql对于我这个不了解相关表和业务的人而言,和天书没有任何区别(毕竟每个关键词都认识,但是连在一起它在查什么我就不得而知了),在一愣之后我意识到一切应该源于此处。
我们业务的缓存设计一般如下图:
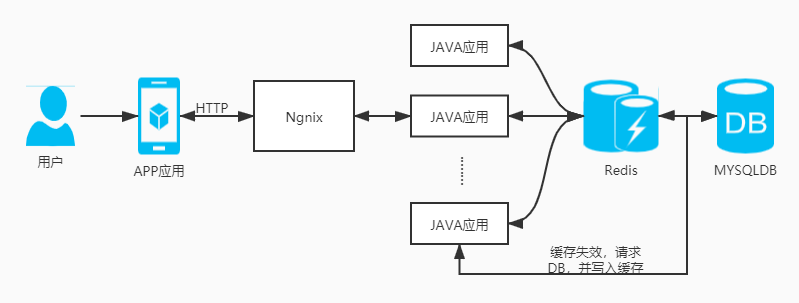
显然问题就是在于当缓存失效的时候,接口将会直接读取数据库,而高压力的查询可能会导致DB的负载过高。即出现了缓存穿透。但是穿透在当前场景不足以致命,而是定时任务由于这个过慢的负载请求,迟迟不能更新数据导致其他对应的key大量失效,即Redis教学局最经典的缓存雪崩。继而情况恶化拖垮主库,其他应用由于迟迟拿不到DB的连接开始阻塞等待,然后基本上有去获取DB连接的服务全部光荣牺牲,然后继而全局服务全部宕机。
3.救火
既然定位了问题所在,而重新恢复服务即是最终要的,于是我们决定将所有服务shutdown(本来就已经处于不可服务状态了,只是防止有新的请求进来),然后将这个数据量巨大的定时任务停掉,暂时上线。与之对应的代价即APP与之相关的页面都是白屏,但只是保证订单和其他业务系统能够正常运转。做完上述动作之后就轮到了修改了这个慢SQL,而由于鄙人不太了解该处的业务,无法在短时间内对这样冗长的SQL做出优化,加之对应的业务同事请假了,所以无奈之下使用俄罗斯套娃方案饮鸩止渴(最快的方案),即在慢SQL加上一个用不过期的缓存,若对应的key不存在,直接返回空。这样的代价就是可能会有业务数据上的bug,但是这样简单高效。
于是这样的一个套娃程序产生了,四个小时之后线上恢复了正常,只是个别模块显示异常。而我们开始细品缓存雪崩的原因:这个定时任务要计算的次数大概是8000 * 200 * 1000 次,而每次计算完成的时间在串行的情况下大概需要70min,不巧的是任务是60min一次。而在此刻,我司的任务调度简单粗暴。。任务会有堆积。之所以今天才出问题,当然要归功于那几位在缓存失效的时候的愿意点击APP应用的用户了呢(用户:???我是谁?我做错了什么?”)
4.防患
到此刻事情才是刚开始,因为上文的救火解决方案是投资人的截图出现在眼前时的急速方案,无需测试即可上线的“稳定方案”,而事实上解决Redis缓存穿透和防止雪崩的办法肯定不是暴力的俄罗斯套娃,而是采用布隆过滤器,使用一个足够大的bitmap,用于存储可能访问的key,不存在的key直接被过滤;访问key未在DB查询到值,也将空值写进缓存,但可以设置较短过期时间。对于集体失效这个事情,处理很简单,比如1小时更新1次的数据每次的失效时间就是60 + Random(x) * 100 Min,散点分布的失效时间直接击碎集体失效的可能性,这样DB不会一下子人就傻了。不过对于穿透这个事情也存在失效一瞬间内的访问,可以加个前置策略:在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。
当然,以上是代码层面的事儿,但是按常理我们应该在慢SQL出现的那一刻就该发现程序的异常之处,所以正常的监控体系也是必不可少的一环。
5.总结
一整天的忙碌让我精疲力尽,投资人的聊天记录糊在脸上,那种疾如风的感觉和亚索打了1-9一样,或许这就是编程的快乐。就心而论,上述问题的解决方案并不是最优解。以工程的角度出发其实是工程结构、表结构设计的开始。首先有了合理的表结构出现就不会有特别复杂的SQL,而良好的工程结构也不会导致超长且依赖度极高的调用链,服务间耦合性低对应的容错和可用性就上去了,而快速发展的业务和复杂多变的需求成了这些东西最大的敌人,但是这个才是真正考验一位工程师能力的地方(实名嘲讽俄罗斯套娃,说的就是我自己,显然表现不及格),就结果而言,程序在Run,投资人满意了,CTO也满意了,大团圆?[无奈]。哦对,之前提到的关于缓存系统的构建,其实应该结合服务和业务情况,对于失效时间的把控,以及对应业务模块的需求一起来完成,当然,至少得注意以下的几点:
1.击穿代价
如果击穿的代价很大,可以加互斥锁,即上文提到的采用SETNX
2.过期时间
这里我有两层意思,即永不过期(高枕无忧但是得考虑keys的数量对RedisDB带来的影响或者监听过期[什么?监听过期,听起来更沙雕了])和随机分布(过期时长肯定是大于更新频次时间的啦,但是要避免集体暴毙,上文就有个 R+Random(x) 的笨比策略)
3.合理的降级策略
上文的我套娃返回了空置,这样一定概率对业务系统产生了影响,但是我要保证的是核心业务的永不宕机,这里有取舍,得看业务。合适的就是最完美的。