为什么要分库分表,如何选择合适的方案
背景
由于业务量突增,加上过亿的表数据查询日渐顶不住业务访问,我们想到的第一个办法就是分库分表,而分库分表的方案五花八门,尤其是经典Sharding JDBC对代码的入侵很是严重,我们迫切需要分表的方案,所以在此背景下我们开始了一系列的调研。
方案调研
Apache ShardingSphere(JDBC-Proxy)
简介:
GitHub:https://github.com/apache/incubator-shardingsphere
官方文档:https://shardingsphere.apache.org/document/current/cn/overview/
作为Apache基金会的分布式数据库中间件项目-ShardingSphere将针对数据水平&垂直拆分、分布式事务、数据服务治理、数据安全等需求提供一套适用于互联网应用架构、云服务架构的多解决方案生态圈。
Apache ShardingSphere是一款开源的分布式数据库中间件组成的生态圈。自从2016年开源以来,不断升级开发新功能、重构稳定微内核,并于2018年11月进入Apache基金会孵化器。
它由京东集团主导,并由多家公司以及整个ShardingSphere社区共同运营参与贡献。其主要的功能模块为:数据分片(分库分表)、分布式事务、数据库治理三大块内容。
使用
这里我不多粘了,文档很棒很清晰,GitHub Issue回复及时可以直接参考
https://shardingsphere.apache.org/document/current/cn/features
优缺点总结
优点:
1. 文档完整,有大厂背书,开源氛围良好
2. 分布式解决方案完整
缺点:(JDBC-Proxy的共同缺点)
1. DB 不透明(BI头大)
2. 分表本质影响写入性能
3. 代码入侵性高,原先写的都需要兼容
MyCat(DB-Proxy)
简介:
官网:http://www.mycat.org.cn/ (这官网是认真的吗?一股浓浓的A货风范...天桥500拍黄片建个站吗?好了我们就事论事)
Github:https://github.com/MyCATApache/Mycat-Server (issue怎么感觉15年是刷的...5000亿数据都来了,我要是选技术框架肯定不选这个...看着就很不对劲)
Mycat是基于开源cobar演变而来,对cobar的代码进行了彻底的重构,使用NIO重构了网络模块,并且优化了Buffer内核,增强了聚合,Join等基本特性,同时兼容绝大多数数据库成为通用的数据库中间件。1.4 版本以后 完全的脱离基本cobar内核,结合Mycat集群管理、自动扩容、智能优化,成为高性能的中间件。致力于开发高性能数据库中间而努力。永不收费,永不闭源,持续推动开源社区的发展。
Mycat吸引和聚集了一大批业内大数据和云计算方面的资深工程师,Mycat的发展壮大基于开源社区志愿者的持续努力,感谢社区志愿者的努力让Mycat更加强大,同时也欢迎社区更多的志愿者,特别是公司能够参与进来,参与Mycat的开发,一起推动社区的发展,为社区提供更好的开源中间件。
看完人家的Readme.md我不想探究了,这个模块我要CV了...上下都透露着他们对于这个浓浓的自豪和自信...我一直认为靠谱的中间件从来都是解决问题出发,而非使用了的“高大上”的技术和方案。吐槽归吐槽,该粘贴的咱继续粘贴。
使用:
在认真阅读了README.md了之后我觉得这个肯定不适合大部分靠谱的Spring项目。不是偏见,而是因为复杂,前面也已经写了两篇了,但是这个从简介来看他们连门面示意图都画的那么粗糙,我觉得问题不只是复杂,还有使用传统xml且无法和配置中心结合(将DB配置塞明文塞到server.xml 2020我干不出这么不优雅的事情,虽然提供了Zk的管理方案但是为啥要用Zk呢?为啥呢为啥呢为啥呢?)。可能这些都是第一印象的偏见,我在文档有附上他们的指引文档(扫了一部分很完整但是却很混乱),其实还是做的一款比较完整的中间件,但是对于我们用处不大(我们很着急)
优缺点总结:
优点:
我没细心钻研,没发现他能在我列的这几个里面突显的优点。
缺点:
1. 接入繁琐
2. 落地大厂少,出事可能除了他们的PDF真就没办法了
3. 链路过长,好好的非得Proxy,把简单是干复杂了,每层都是在增加响应时间好不
PolarDB(DB-Based)
简介:
PolarDB是阿里云自研的下一代关系型云数据库,兼容MySQL、PostgreSQL、Oracle引擎,存储容量最高可达100TB,单库最多可扩展到16个节点,适用于企业多样化的数据库应用场景。
PolarDB采用存储和计算分离的架构,所有计算节点共享一份数据,提供分钟级的配置升降级、秒级的故障恢复、全局数据一致性和免费的数据备份容灾服务。PolarDB既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、自我迭代的优势。
PolarDB兼容Oracle数据库提供公共云和专有云形态,其中专有云形态支持CentOS、UOS、麒麟等操作系统,支持X86架构CPU以及ARM架构CPU(飞腾等)。
使用:
PolarDB本质上是数据源的切换,相当于从原先的RDS切换到了PolarDB,所以在项目配置当中只需要像正常配置JDBC连接一样即可,对于线上的一键切换方案可以利用Spring动态数据源的做这件事,其实相对是比较简单的,我们需要的就是买买买和改改DB连接。其中有些部分概念如下表:
| 集群 | Cluster | PolarDB采用集群架构,一个集群包含一个主节点和多个读节点。集群可以跨可用区(AZ),不能跨地域(Region)。 | 集群 | Cluster |
|---|---|---|---|---|
| 节点 | Node | PolarDB集群由多个物理的节点构成,目前每个集群中的所有节点可分为两类,分别为主节点(Writer)和只读节点(Reader)。每类节点关系对等,规格相同。 | 节点 | Node |
| 主节点 | Writer | 主节点,也叫读写节点,一个集群有一个主节点,可读可写。 | 主节点 | Writer |
| 读节点 | Reader | 只读节点,一个集群最多15个。 | 读节点 | Reader |
| 故障切换(主备切换) | Failover | 提升一个只读节点为主节点。 | 故障切换(主备切换) | Failover |
| 规格 | Class | 每个节点的资源配置,例如2核4GB。 | 规格 | Class |
| 访问点 | Endpoint | 访问点(Endpoint)定义了数据库的访问入口,也可以称之为接入点。一个集群提供多个Endpoint,每个Endpoint后面接一个或多个节点。例如,主访问点永远指向主节点,集群Endpoint提供了读写分离能力,后挂主节点和只读节点。Endpoint中主要包含的是数据库链路属性,例如读写状态、节点列表、负载均衡、一致性级别等配置信息。 | 访问点 | Endpoint |
| 访问地址 | Address | 访问地址是访问点在不同网络平面中的载体,一个Endpoint可能包含私网和公网两种访问地址。访问地址中包含了一些网络属性,例如,域(Domain)、IP地址、专有网络 (VPC)、交换机(VSwitch)等。 | 访问地址 | Address |
| 主访问点(主地址) | Primary Endpoint | 主节点(Writer)的访问点,当发生故障切换(Failover)后,会自动指向到新的主节点。 | 主访问点(主地址) | Primary Endpoint |
| 集群访问点(集群地址) | Cluster Endpoint | 整合集群下所有节点,对外提供一个统一的访问入口,可以设置为只读或可读可写(自动读写分离),具有自动弹性、读写分离、负载均衡、一致性协调等能力。 | 集群访问点(集群地址) | Cluster Endpoint |
| 地域 | Region | 地域是指物理的数据中心。一般情况下,PolarDB集群应该和ECS实例位于同一地域,以实现最高的访问性能。 | 地域 | Region |
| 可用区 | Availability Zone(AZ) | 可用区是指在同一地域内,电力和网络互相独立的物理区域。在同一地域内可用区与可用区之间内网互通,可用区之间能做到故障隔离。 | 可用区 | Availability Zone(AZ) |
| 主可用区 | Primary AZ | PolarDB主节点所在可用区。 | 主可用区 | Primary AZ |
| 集群可用区 | Cluster AZ | 集群数据分布的可用区。一个集群的数据会自动在两个可用区间做冗余,用于灾难恢复。只支持在这些可用区间进行节点迁移。 | 集群可用区 | Cluster AZ |
| 集群 | Cluster | PolarDB采用集群架构,一个集群包含一个主节点和多个读节点。集群可以跨可用区(AZ),不能跨地域(Region)。 | 集群 | Cluster |
其大致结构如图:
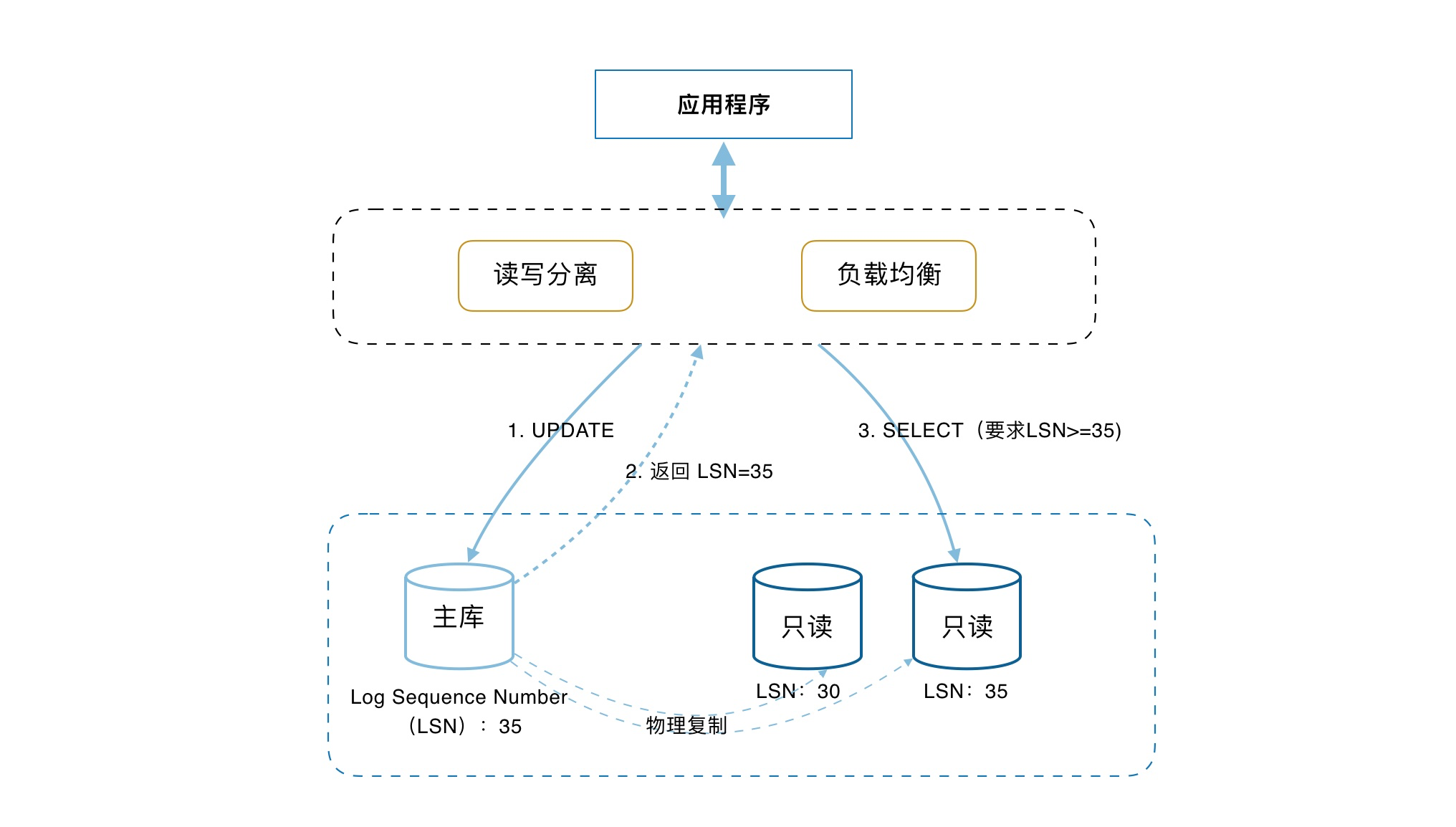
更多详细的情况可以直接去阿里云的官网查看,文章末尾也写了连接,可以直接点
优缺点总结:
优点:
1. 容量大,Parallel-Raft协议
2. 读一致性,读写分离
3. 多可读节点,一写多读
4. 项目切换简单,语言兼容性相较于前面几款要好的多
缺点:
1. 贵
2. 同步数据也花钱
3. 大厂落地经验少,不像开源软件文档多Issue有人理,一出事除了找阿里云客服之外叫天天不应叫地地不灵
最终选定
在最后的关头我们当然是选择PolarDB了....也就是约等于没敢分。为什么?因为需要重写查询,对应的重构成本较高,而使用PolarDB我们则可以利用读写分离来减轻一部分压力,但是慢查依旧存在怎么办?当然是能优化索引就优化索引,无法优化索引的话我们自然也有办法:通过ElasticSearch的引入来解决查询慢的情况,将繁重的查询转移到Es上面,这一样一来PolarDB的节点压力就更小了。显然这次的方案选择并不是很多,只是有几个比较有代表性的,其实有更多(TDDL/Zebra/Vitess/Atlas...等等),多的原因是我们需要在十五天之内上线,其实打心底我是比较支持Sharding-JDBC的,总体上如果时间比较充裕,我肯定会选择Sharding-JDBC。