前言
前段时间我司服务集体上微服务,离容器化就差几个实验了,由于我们后端的任务多是提供RestAPI接口,并没有提供模板渲染、JSP页面的这些内容。而作为接口提供方的我们,一直以来都是通过Nginx做一层域名到Tomcat的流量转发,其配置规则由运维控制,配置文件需要控制Nginx的conf文件,不论是API鉴权,还是监控,包括服务的健康检查、日志都显得十分鸡肋。作为API层我们急需一款能够提供鉴权、日志、流量控制、负载均衡、端点管理于一体的网关层。
调研
其实如果网关层存在一定的小缺陷是可以容忍的,只要适合我们的业务和整体服务架构,那么将会是我们的最优选择。由于刚刚上了SpringCloud的船,我们的目光自然而然放到了SpringCloud全家桶的Zuul。
1.Zuul
作为全家桶家族成员,的确完美契合目前的项目框架。但是伴随着有一个新的问题。Zuul的各种功能都是基于底层的Filter的,所以如果想快速上车使用框架带来的功能,那就得摸清Zuul的各种配置详细的功能以及配置方法,其中如果要配置EndPoints和url的拦截规则等,则需要在代码当中去修改配置文件,虽然配置文件走的是Apollo的热更新,但是无疑这样的发展趋势则是将API网关的管理移到了Apollo上,这样的想法很危险。加上如果做定制开发,需要做的事情过多。加上团队真正对Zuul熟悉且有实际线上经验的人并没有(小声说),只能将目光移向下一个:
2.Kong
这个是基于Nginx的服务器,是可以通过插件扩展已有功能,这些插件在 API 请求响应循环的生命周期中被执行。插件使用 Lua 编写,而且Kong还有如下几个基础功能:HTTP 基本认证、密钥认证、CORS( Cross-origin Resource Sharing,跨域资源共享)、TCP、UDP、文件日志、API 请求限流、请求转发以及 nginx 监控。当看见插件是使用Lua编写的时候我们就意识到这个不适合。因为团队没人会这个(小声说),只能继续寻找:
3.Gravitee
Java。
Java编写。
纯Java编写。
我们似乎找到了最终的答案。
首先是单独部署的网关,配置由MangoDb存储,日志使用elasticsearch存储,完善的账户管控、项目管控、计划管理,旗下涵盖API鉴权、日志管理、服务监控、灰度发布、负载均衡,组件可扩展,组合Swagger可以顺带有API文档。属实我们的不二之选。缺点也很明显,他们官网的版本依旧在高强度更新当中(至今已中招Health Check,暗示不稳定),相较Nginx在响应时间和QPS上有点不容乐观(以我们的业务量依旧处于仍可接受的状态),官方文档完善程度很是一般官方文档。但是无脑的界面配置和自带监控dashboard简直瞬间解决我们当下的问题,我们决定上车。
1.Gravitee的基本情况
Gravitee的核心分为三个部分:
1.gravitee-gateway
2.gravitee-management-webui
3.gravitee-management-rest-api
其中2、3是作为管理客户端存在,而1则是网关本身,在安装之前提前准备好配置存储的DB:MangoDB和日志存储ElasticSearch。这两个安装好之后可以去他们的Github主页下载一下上面提供的三个部分:https://github.com/gravitee-io
下载好之后解压,修改配置文件(gravitee.yml)中的DB配置(在这里甚至能够看到Vertx的配置项,有关Vertx:Vert.X简介),进入gravitee-gateway的bin目录执行一下gateway,不出问题核心gravitee-gateway已经能动了。接下来便是gravitee-management-webui的启动,既然是网页应用,它本身不提供Server,所以部署webui的机器需要安装一下Nginx,装完Nginx之后解压2、3,进入ui的目录修改其constants.json的配置,使其主机地址为当前主机地址,保存之后访问自己的Nginx,进入了其管理界面。接下来的操作变成了鼠标流:
你可以创建一个新的API,来作为一个新的项目出现。对应一个新的API,可以配置一个Application请求计划,通过请求计划订阅API来实现绑定,对应的可以将API-Key放在请求计划当中,这样普通接口就加上了一层基本的鉴权,当然,这个部分是高度自由和定制化的,你可以通过自定义的拦截器来实现鉴权(比如我司常用的UserToken+设备Key)。对应API的目录下,你可以定义Proxy代理配置,可以将一些路由动态转发至你配备的EndPoints端点上,即微服务的不同容器地址,而配置这些路由的Police政策,通常可以使用EL表达式来匹配,对比Nginx的配置,这个的配置难度降到了最低点。而在同一Endpoints下Group内,可以配备多台机器,提供你不同的权重配置来决定流量分配,每台机器不同的健康检查和故障转移使得服务高可用。
而上面这些只是针对API的内容,每个API具有不同用户的操作权限,设有拥有着和其他用户等一系列权限管理,其中包括了桌面通知、邮件预警等功能,日志也是将完整的Trace打印,提供Http状态码、url等快速检索。
说了这么多其方便的地方,也说一下其可用性。下面是测试其性能机器的参数(手动感谢运维大佬@强哥):
gravitee版本:1.22.2
MongoDB版本:3.6.10
elasticsearch版本:5.6.14
VM配置:
堆内存初始值4g
堆内存最大值4g
CMS垃圾回收机制
系统配置
net.ipv4.ip_forward = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
kernel.sysrq = 0
kernel.core_uses_pid = 1
net.ipv4.tcp_syncookies = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.shmmax = 68719476736
kernel.shmall = 4294967296
net.ipv4.tcp_max_tw_buckets = 40000
net.ipv4.tcp_sack = 1
net.ipv4.tcp_window_scaling = 1
net.core.wmem_default = 8388608
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.netdev_max_backlog = 262144
net.core.somaxconn = 65535
net.core.optmem_max = 81920
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_mem = 94500000 915000000 927000000
net.ipv4.tcp_rmem = 4096 87380 8388608
net.ipv4.tcp_wmem = 4096 87380 8388608
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.tcp_keepalive_intvl = 60
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_fin_timeout = 30
vm.swappiness = 0
net.ipv4.ip_local_port_range = 1024 65535
API配置:
连接超时:60秒
读取超时:60秒
最大连接数:100000
API网关的最大吞吐量
测试参数:
线程:4
连接数:500
持续时长:30秒
结果:
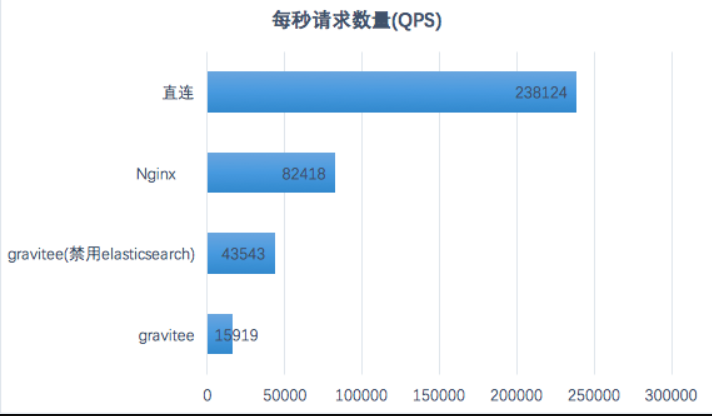
结论:
CPU:大压力下gravitee所在主机的CPU占用率接近100%,elasticsearch所在主机的CPU占用率也在80%以上但不是主要瓶颈。
最大连接数
线程:4
连接数:70000
QPS:1000
持续时长:10分钟
请求超时:10分钟
结果:服务抛出异常java.io.IOException: Too many open files,达到系统最大打开文件数,但请求处理正常,此时API网关自身统计的连接数为64450
请求响应时间
线程:4
连接数:100
QPS:1000
持续时长:30秒
结果如下图:

稳定性
线程:4
连接数:500
持续时长:30分钟
结果:
- 开启elasticsearch-最大吞吐量(QPS:15000)
请求时间:平均44.2秒 最大8.79分钟
请求错误率:0.162%
5分钟左右开始频繁FULLGC(每秒2-3次),共计3555次
出现请求超时
API网关报异常io.reactivex.exceptions.OnErrorNotImplementedException: The timeout period of 120000ms has been exceeded while executing POST /_bulk for host
- 开启elasticsearch-80%最大吞吐量(QPS:12000)
请求时间:平均2.43毫秒 最大203.39毫秒
请求错误率:0%
- 禁用elasticsearch-最大吞吐量(QPS:43000)
请求时间:平均13.68秒 最大2.83分钟
请求错误率:0%
- 禁用elasticsearch-80%最大吞吐量(QPS:34000)
请求时间:平均3.46毫秒 最大305.15毫秒
请求错误率:0%
结论:当开启elasticsearch时,长时间接收最大吞吐量的请求下会有大量内存驻留在JVM的老年代不能被FULLGC收集,最终会出现频繁FULLGC,严重影响请求响应时间和成功率。
在80%最大吞吐量下表现稳定,性能损耗不大。
Policy插件和配置的影响
线程:4
连接数:500
持续时长:30秒
结果:
- 开启配置文件中的services-metrics(用于提供监控指标接口)
QPS:14117
- 开启配置文件中的services-metrics并且开启elasticsearch作为reporter
QPS:9709
- 在管理端对API开启policy的Rate-Limiting(限流10万QPS)
QPS:7960,CPU占用增加
API动态发布的影响
线程:4
连接数:500
持续时长:30秒
结果:
QPS10000以下:错误率0%
QPS超过10000:错误率小于0.005%
故障恢复测试
MongoDB宕机及恢复
测试在API网关运行时MongoDB突然宕机对访问成功率和性能的影响,测试MongoDB恢复后API网关是否有自动重连机制并是否对访问造成影响
线程:4
连接数:500
QPS:15000
持续时长:10分钟
结果:
MongoDB宕机对运行中的API网关没有影响,访问成功率100%,QPS没有下降
MongoDB恢复后API网关自动重连到MongoDB,并且对访问成功率和QPS都没有造成影响
Elasticsearch宕机及恢复
测试在API网关运行时Elasticsearch突然宕机对访问成功率和性能的影响,测试Elasticsearch恢复后API网关是否有自动重连机制并是否对访问造成影响
线程:4
连接数:500
QPS:15000
持续时长:10分钟
结果:
Elasticsearch宕机对运行中的API网关没有影响,访问成功率100%,QPS没有下降
Elasticsearch恢复后API网关自动重连到Elasticsearch,并且对访问成功率和QPS都没有造成影响
测试结果综述:
- QPS
API网关QPS相较于Nginx差距比较大,在常规请求量的情况下请求响应时间损耗不大。
API网关是CPU密集型服务,主要性能瓶颈在API网关所在主机的CPU,Elasticsearch主机的CPU占用也较高,MongoDB主机整体压力不大。 - 连接数
当连接数达到70000且请求量不多时API网关会报异常java.io.IOException: Too many open files,达到系统最大打开文件数,但未观察到请求失败的情况。 - 稳定性
当开启Elasticsearch时JVM成为影响系统稳定性的最大因素,长时间高负载会导致频繁FULLGC影响请求成功率和吞吐量,有内存溢出风险。
当禁用Elasticsearch时系统表现比较稳定。
在80%最大吞吐量下表现稳定,性能损耗不大。 - 配置和插件
是否启用Elasticsearch作为API网关Reporter对API网关的QPS影响很大。
是否开启配置文件中的services-metrics(用于提供监控指标)对API网关的QPS影响很大。
是否开启APi限流(限流值远大于QPS测试值)对API网关的QPS影响很大。 - 动态发布
API动态发布对性能和可用性影响不大。 - 故障恢复
对MongoDB和Elasticsearch的故障宕机可以做到不影响服务性能和可用性,具有自动重连机制,MongoDB和Elasticsearch从故障恢复后可以自动重连恢复数据同步。 - 其他
测试中发现API网关1.21.2版本开启policy的rate-limit时会报异常Failed to instantiate io.gravitee.repository.ratelimit.model.RateLimit using constructor NO_CONSTRUCTOR with arguments,参见https://github.com/gravitee-io/issues/issues/1748。
大概高可用的方案
- API网关服务高可用
API网关可以部署多实例,通过MongoDB进行数据同步,日志可以输出到Elasticsearch或采集到阿里云日志服务(目前依旧未将日志接入阿里云,MangoDB是存放Policy配置的..) - MangoDB高可用
采用MongoDB的多副本集群方案,数据读取和写入到主节点,副本节点从主节点进行数据同步,当主节点宕机后从副本节点中重新选举出主节点,对于调用MongoDB的API网关来说整个MongoDB集群是透明
MangoDB配置:
management:
type: mongodb
mongodb:
servers:
- host: ${ds.mongodb1.host}
port: ${ds.mongodb1.port}
- host: ${ds.mongodb2.host}
port: ${ds.mongodb2.port}
- host: ${ds.mongodb3.host}
port: ${ds.mongodb3.port}
dbname: ${ds.mongodb.dbname}
username: ${ds.mongodb.username}
password: ${ds.mongodb.password}
ratelimit:
type: mongodb
mongodb:
servers:
- host: ${ds.mongodb1.host}
port: ${ds.mongodb1.port}
- host: ${ds.mongodb2.host}
port: ${ds.mongodb2.port}
- host: ${ds.mongodb3.host}
port: ${ds.mongodb3.port}
dbname: ${ds.mongodb.dbname}
username: ${ds.mongodb.username}
password: ${ds.mongodb.password}
ds:
mongodb:
dbname: gravitee
username: gravitee
password: xxx
mongodb1:
host: 192.168.168.xxx
port: 27017
mongodb2:
host: 192.168.168.xxx
port: 27017
mongodb3:
host: 192.168.168.xxx
port: 27017
- API网关的Elasticsearch高可用
reporters:
elasticsearch:
endpoints:
- http://${ds.elastic1.host}:${ds.elastic1.port}
- http://${ds.elastic2.host}:${ds.elastic2.port}
- http://${ds.elastic3.host}:${ds.elastic3.port}
security:
username: ${ds.elastic.username}
password: ${ds.elastic.password}
ds:
elastic:
username: gravitee
password: xxx
elastic1:
host: 192.168.168.xxx
port: 9200
elastic2:
host: 192.168.168.xxx
port: 9200
elastic3:
host: 192.168.168.xxx
port: 9200
2.Gravitee在工程中的实践
既然选择Java作为开发语言的Gravitee,为了能使其更好地在我们的项目中运行,我们需要将一部分服务使用新的网关。首先我们把目光放在了我们内部的Mis管理系统,借着Mis管理系统前后端分离的机会,我们在Gravitee创建了新的应用和对应的端点,合理创建了Group(就一个服务似乎也使合理创建呢..),配置了两台机器作为同组的Endpoints,负载均衡使用加权轮询法(两台机器,但是峰值机器的压力不同,通过配置不同的权重来达到流量转发)。在此之后加入了路由配置(Dynamic Routing)和请求方式配置(由于我们是假的RestFul,只有Get和Post请求,将其他请求禁用)。添加访问的APIKeys,将Swagger文档给一些只读用户开放。
这只是第一步。我们编写我们公司的单点登录的鉴权插件,配置到了Gravitee,网关层就完成了基本的用户校验,并且通过本地线程变量将UserId等用户登录信息一路相承。
一切似乎都很正常也很成功。
可惜好景不长:
3.Gravitee翻车实况
我们的高可用方案原先其实是通过部署两台机器交替发版来完成服务高可用,但是除去Nginx的转发方案似乎当前没有特别好用的方法了,而在微服务当中健康检查是个很常见的功能,甚至SpringBoot就提供了完整的服务健康检查类:只需要引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
作为分布式系统的网关层,Graviteer自然也提供了健康检查的接口:通过定时的Http请求去获取服务当前的状态,而正常的http返回状态则表明服务当前是可用的。很轻易的我就在服务打开的健康检查的配置并且自定义了符合项目的健康检查接口。可是却遭遇的Gravitee的第一个翻车点:
由于在添加Gravitee的健康检查接口时出现了无法保存的情况(Gravitee.io/management的锅)
在修改一番之后发现仍然无效的情况下只好做了伸手党:
https://github.com/gravitee-io/issues/issues/2420
但是作者似乎不怎么待见我这个伸手党...更加难受的是他的日志管理和ApiKey管理..毕竟作为网关层日志基本上是海量的,但是存入ES需要时间,而往往日志都不是即时的,除此之外还有监控。他只是对接口的Http状态做了汇总和探查,但是对于服务本身的Cpu、内存、GC、等重要数值并没有做监察,只能我们自身去做。
4.真正的用法
当服务规模达到30个以上的时候,再通过分组+配置动态路由的方式就显得非常难受和复杂,所以在架总和运维努力下最终我们的玩法则是:K8s + Gravitee ,将监控、日志等不好处理的东西降级到容器级别,然后由容器负责负载均衡等,向网关层提供基本的接口,最终由网关层对外对接,结构如下图:
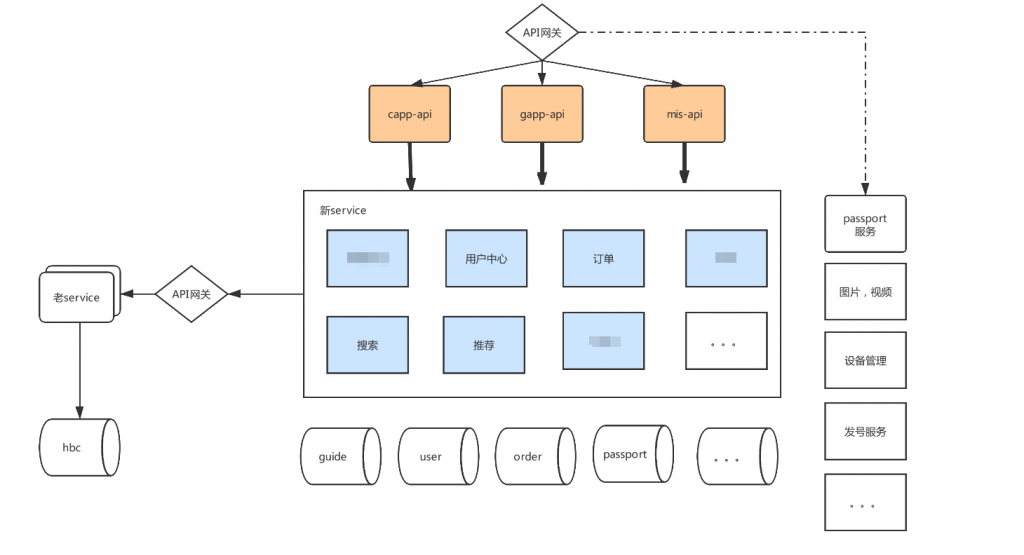
5.总结
由此可见,最适合的就是最值得选择了,目前我们我们已经有两个APP和一个Web应用上了Gravitee的车,虽然健康检查依旧没人回复,只能更新一下把版本重新试一下了。在业务繁重的情况下想要完善这个东西,的确需要一些时间去迭代和优化,循序渐进的打造一个稳定可靠的网关。
很荣幸能够看到这篇博文。我们现在也遇到了类似的问题。公司服务众多,各个版本的服务众多。由于前期问题,各种子域名,各种nginx转发,出口不一致。目前我的想法是使用kong作为流量网关,另外需要寻找一个比较合适的作为业务网关。有两个问题想要问下,gravitee在鉴权方面怎么样?二开成本怎么样?因为有一些个性化需求,例如提供给合作公司接口,针对用户要做一些监控。
@千山 鉴权可以通过policy插件的方式增加,你的鉴权可以是个单独的服务,而对应的配置规则需要你写schema.xml,相对和网关服务的耦合性不是很高,二开的话我觉得Java程序员应该很好上手,至于监控的话在我们实践当中他的日志存储在es的,相对查询界面没有像elk那么完善,不过他的网关还好,dashboard也经过n多迭代,现在总体来说如果业务可以尝试一下。(评论是因为之前被ghs的骚扰无奈全量上了审核,周末打游戏邮件开了免打扰没看到你的消息 抱歉哈//不过现在加了微信就无所谓了…)
不能评论吗